다익스트라 알고리즘 (데이크스트라)
하나의 정점에서 다른 모든 정점까지의 최단 경로를 구하는 문제 (single source shortest path problem)
음의 가중치가 없는 그래프에서 한 노드에서 다른 모든 노드까지의 최단거리를 구하는 알고리즘이다.
방향 그래프, 무방향 그래프 모두 상관없으나, 가중치가 음수인 edge가 단 하나라도 존재하면 이 알고리즘은 사용할 수 없다.
에츠허르 다익스트라가 고안한 알고리즘으로, 그가 처음 고안한 알고리즘은의 시간 복잡도를 가졌다.
이후 우선순위 큐(힙 트리)등을 이용한 더욱 개선된 알고리즘이 나오며, 의 시간복잡도를 가지게 되었다.의 시간복잡도를 가지는 이유는 각 노드마다 미방문 노드 중 출발점으로부터 현재까지 계산된 최단 거리를 가지는 노드를 찾는데
의 시간이 필요하고, 각 노드마다 이웃한 노드의 최단 거리를 갱신할때
의 시간이 필요하기 때문이다.
다익스트라 알고리즘이 하나의 노드로부터 최단경로를 구하는 알고리즘인 반면, 플로이드-워셜 알고리즘은 가능한 모든 노드쌍들에 대한 최단거리를 구하는 알고리즘이다.
다익스트라 알고리즘을 확장시킨 알고리즘이 A* 알고리즘이다.
알고리즘 조건: 간선들은 모두 양의 간선들을 가져야 한다.
알고리즘 원리.
P[A][B]는 A와 B 사이의 거리라고 가정한다.
-
출발점으로부터의 최단거리를 저장할 배열 d[v]를 만들고, 출발 노드에는 0을, 출발점을 제외한 다른 노드들에는 매우 큰 값 INF를 채워 넣는다. (정말 무한이 아닌, 무한으로 간주될 수 있는 값을 의미한다.) 보통은 최단거리 저장 배열의 이론상 최대값에 맞게 INF를 정한다. 실무에서는 보통 d의 원소 타입에 대한 최대값으로 설정하는 편.
-
현재 노드를 나타내는 변수 A에 출발 노드의 번호를 저장한다.
-
A로부터 갈 수 있는 임의의 노드 B에 대해, d[A] + P[A][B]와 d[B]의 값을 비교한다. INF와 비교할 경우 무조건 전자가 작다.
-
만약 d[A] + P[A][B]의 값이 더 작다면, 즉 더 짧은 경로라면, d[B]의 값을 이 값으로 갱신시킨다.
-
A의 모든 이웃 노드 B에 대해 이 작업을 수행한다.
-
A의 상태를 "방문 완료"로 바꾼다. 그러면 이제 더 이상 A는 사용하지 않는다.
-
"미방문" 상태인 모든 노드들 중, 출발점으로부터의 거리가 제일 짧은 노드 하나를 골라서 그 노드를 A에 저장한다.
-
도착 노드가 "방문 완료" 상태가 되거나, 혹은 더 이상 미방문 상태의 노드를 선택할 수 없을 때까지, 3~7의 과정을 반복한다.
이 작업을 마친 뒤, 도착 노드에 저장된 값이 바로 A로부터의 최단 거리이다. 만약 이 값이 INF라면, 중간에 길이 끊긴 것임을 의미한다.
7번 단계에서, 거리가 가장 짧은 노드를 고르는 것은 공짜가 아니다.
모든 노드를 순회해야 하므로 시간복잡도에 결정적인 영향을 미치게 되는데, 이때 제대로 구현된 우선순위 큐를 활용한다면 이 비용을 줄일 수 있다.
최단거리를 갱신할 때 우선순위 큐에도 <위치, 거리>의 쌍을 넣어주고, 거리가 가장 짧은 노드를 우선순위 큐를 이용해 고르면 된다.
이진 힙을 이용해 구현한 우선순위 큐의 경우 O(lg N) 출력에 O(lg N)이므로, 모든 노드 순회(O(N))보다 저렴하다.
우선순위 큐 구현에 피보나치 힙을 사용한 경우 삽입은 평균적으로 O(1), 출력에는 O(lg N)이 걸려 이론적으로 더 나은 시간복잡도를 얻을 수 있다.
단 이진 힙이 훨씬 간단하여 연산에 소요되는 시간이 빠르기 때문에, 엣지의 개수가 적은 경우에는 이진 힙을 사용하는 것이 더 나을 수 있다.
https://tinyurl.com/y287lhew
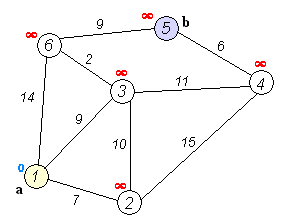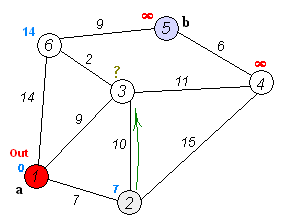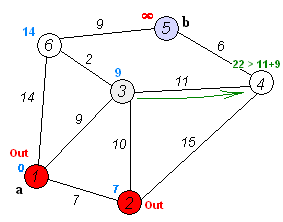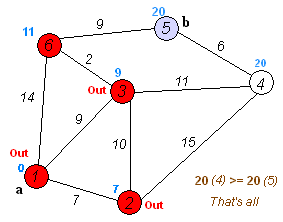
다익스트라 알고리즘 예시

아래쪽 교차로가 현재 위치일 때 갱신되는 상황을 나타낸 그림이다.
각 교차로에는 현재까지의 최단 거리가 적혀있다. 현재 위치에서 이웃 교차로까지 5의 거리로 갈 수 있다고 할 때,
이웃교차로에는 15의 거리로 도착할 수 있다.
왼쪽 교차로는 이미 다른 경로를 통해 13의 거리로 도착할 수 있으므로 갱신하지 않고,
오른쪽 교차로는 더 짧은 거리로 도착할 수 있으므로 갱신한다.
가운데 교차로는 방문하지 않은 교차로이므로 갱신한다.
이 과정은 현재 거리에 도로 길이를 더한 값과 교차로에 쓰여진 값을 비교해서 구할 수 있다.
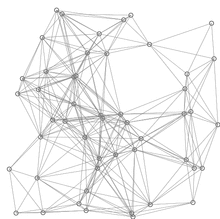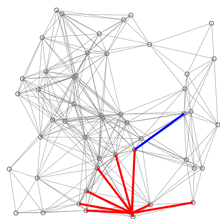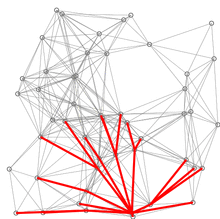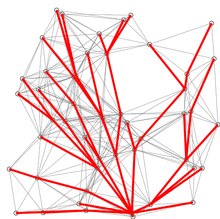
유클리드 거리에 기반한 다익스트라 알고리즘의 시연이다.
빨간색 선은 최단 경로이다. 다시 말해, u와 [u]를 연결하는 선이다.
파란 선은 변 경감이 이루어지는 위치를 나타낸다.
즉, v와 Q에 있는 꼭짓점 u를 연결하는 선으로, 소스에서 v까지 가는 더 짧은 경로를 나타낸다.
예를 들어, 다음과 같은 네트워크가 존재한다고 가정하자.
먼저, A 라우터의 목표는 F까지의 최단 거리 계산이며, 수단으로는 다익스트라 알고리즘을 활용한다.
이때, 각 데이터의 의미는 다음과 같다.
-
S = 방문한 노드들의 집합
-
d[N] = A -> N까지 계산된 최단 거리
-
Q = 방문하지 않은 노드들의 집합
1. 다익스트라 알고리즘은 아직 확인되지 않은 거리는 전부 초기값을 무한으로 잡는다.

-
출발지를 A로 초기화했기 때문에, 출발지와 출발지의 거리는 방문할 필요도 없이 당연히 0 값을 가진다. 즉, d[A]=0이 된다. (A노드를 방문한 것은 아니다.)
-
출발지를 제외한 모든 노드들도 아직 방문하지 않았기에, d[다른 노드]=무한이 된다.
-
Q는 방문하지 않은 노드들의 집합이므로, 초기화할 때는 모든 노드들의 집합이 된다.
-
S는 공집합 상태이다.
2. 루프를 돌려 이웃 노드를 방문하고 거리를 계산한다.

-
루프의 시작은 거리가 최소인 노드(d[N]이 최소값인 노드 N)를 Q(방문하지 않은 노드의 집합)에서 제거하고, 그 노드를 S(방문한 노드의 집합 및 최소 경로)에 추가한다. 즉, N을 '방문한다'는 의미이다.
-
이후, 모든 이웃 노드와의 거리를 측정하여 d[N](=출발지로부터 N까지 계산된 최소 거리값) + (N과 이웃 노드 간의 거리값) = (출발지부터 이웃 노드까지의 거리값)이 계산된다.
-
다만, 지금은 첫 번째 루프만을 끝낸 상태이므로, 단순히 0 + (이웃 노드와 출발지 사이의 거리값) = (출발지와 이웃 노드 간의 거리값)이 각 이웃 노드에 기록된다. 따라서, d[B] = 10, d[C] = 30, d[D] =15로 값을 변경한다.
3. 첫 루프 이후의 그래프의 상태가 업데이트되는 방식
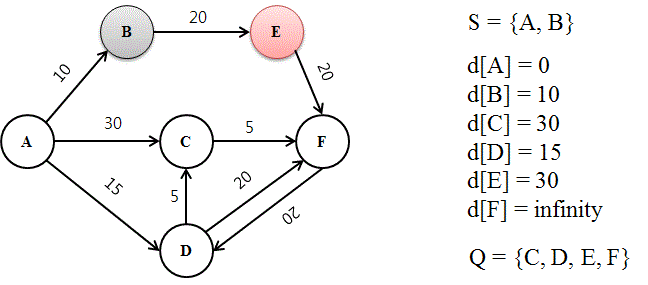
이제 루프가 반복적으로 작동하는 방법을 설명한다. 밑의 그림들 또한 루프 안에서 알고리즘이 진행되는 순간들을 반복 설명한다.
-
이전에 설명했듯이, 방문할 노드는 Q에 남아있는 노드들 중 d[N] 값이 제일 작은 것으로 선택된다. 따라서, Q = {B, C, D, E, F} 중 B가 d[B] = 10으로 제일 작은 값을 가지므로, B를 방문하여 S에 추가하고 Q에서 제거한다.
-
이제, B의 이웃 노드들을 모두 탐색하여 거리를 재고 d[N]에 기록한다. B의 이웃 노드는 E 뿐이므로, d[E] 값이 무한에서 d[B]+(B와 E 사이의 값 20) = 30 으로 업데이트된다. 여기서 d[B] 값을 더하는 이유는 출발지부터의 거리값을 재기 위해서다.
4. 더 빠른 경로를 발견한 경우

-
3번째 그림에서 설명했듯이, 이번에 선택·방문되는 노드는 D이다. Q의 원소 중에서 제일 낮은 d[N] 값을 가지고 있기 때문이다. 그래서, S에 D가 추가되어 있다.
-
이제 D의 이웃 노드들(C, F)의 거리를 잰 후, d[N]값을 업데이트한다. 특별한 상황은 d[C]의 값이 A를 방문할 때 이미 계산되어 30으로 정해져 있었으나, D를 방문하여 C와의 거리를 확인해 보니 20으로 더 짧은 최단 경로라 판단. 그러므로, d[C]의 값을 30에서 20으로 변경한다.
-
d[F]의 경우는 원래의 값이 무한이므로, 더 작은 값인 15+20=35로 변경한다.
5. 또 다른 반복 루프 상황

-
Q = {C,E,F}에서 d[C] = 20으로 C를 방문하여, S는 {A, B, D, C}가 되었다.
-
다시 이웃 노드와의 거리 계산을 해보니, 이번에는 (A→D) + (D→F) = 15 + 20 = 35보다, (A→D) + (D→C) + (C→F) = 15 + 5 + 5 = 25로 더 작은 값을 가지는 것이 발견되었다. d[F] = 25로 업데이트한다.
이 일련의 과정이 반복되어 Q가 공집합이 되었다면, 남아 있는 데이터로 추론하여 최단 거리를 결정한다.
마지막 루프 이후,
-
S = {A, B, D, C, F, E} (방문한 순서대로 정렬)
-
d[A] = 0
-
d[B] = 10
-
d[C] = 20
-
d[D] = 15
-
d[E] = 30
-
d[F] = 25
-
Q = ∅
목적지가 F였으므로, A→D→C→F가 최단 경로이며, 거리는 25로 결정된다.
https://tinyurl.com/yyoa4tv2
다익스트라 알고리즘 파이썬 코드
import sys
#system library import
def dijkstra(K, V, graph):
#Dijkstra 함수 시작
#입력으로 K, V, graph를 받는다
INF = sys.maxsize
# s는 해당 노드를 방문 했는지 여부를 저장하는 변수이다
s = [False] * V
# d는 memoization을 위한 array이다. d[i]는 정점 K에서 i까지 가는 최소한의 거리가 저장되어 있다.
d = [INF] * V
d[K - 1] = 0
while True:
m = INF
N = -1
# 방문하지 않은 노드 중 d값이 가장 작은 값을 선택해 그 노드의 번호를 N에 저장한다.
# 즉, 방문하지 않은 노드 중 K 정점과 가장 가까운 노드를 선택한다.
for j in range(V):
if not s[j] and m > d[j]:
m = d[j]
N = j
# 방문하지 않은 노드 중 현재 K 정점과 가장 가까운 노드와의 거리가 INF 라는 뜻은
# 방문하지 않은 남아있는 모든 노드가 A에서 도달할 수 없는 노드라는 의미이므로 반복문을 빠져나간다.
if m == INF:
break
# N번 노드를 '방문'한다.
# '방문'한다는 의미는 모든 노드를 탐색하며 N번 노드를 통해서 가면 더 빨리 갈 수 있는 노드가 있는지 확인하고,
# 더 빨리 갈 수 있다면 해당 노드(노드의 번호 j라고 하자)의 d[j]를 업데이트 해준다.
s[N] = True
for j in range(V):
if s[j]: continue
via = d[N] + graph[N][j]
if d[j] > via:
d[j] = via
return d
if __name__ == "__main__":
V, E = map(int, input().split())
#V는 vertex이고 E는 edge임
K = int(input())
#K는 출발노드
INF = sys.maxsize
graph = [[INF]*V for _ in range(V)]
#그래프를 그려놓는다
for _ in range(E):
u, v, w = map(int, input().split())
graph[u-1][v-1] = w
#좌표입력
for d in dijkstra(K, V, graph):
print(d if d != INF else "INF")
#다익스트라 알고리즘 실행다익스트라 알고리즘 의사 코드
function Dijkstra(Graph, Source):
dist[source] ← 0 // 소스와 소스 사이의 거리 초기화 --출발지와 출발지의 거리는 당연히 0--
prev[source] ← undefined // 출발지 이전의 최적 경로 추적은 없으므로 Undefined
create vertex set Q //노드들의 집합 Q(방문되지 않은 노드들의 집합) 생성 시작
for each vertex v in Graph: // Graph안에 있는 모든 노드들의 초기화
if v ≠ source: // V 노드가 출발지가 아닐 경우(출발지를 제외한 모든 노드!)
dist[v] ← INFINITY // 소스와 V노드 사이에 알려지지 않은 거리 --얼마나 먼지 모르니까-- = 무한값 ( 모든 노드들을 초기화하는 값)
prev[v] ← UNDEFINED // V노드의 최적경로 추적 초기화
add v to Q // Graph에 존재하고 방금 전 초기화된 V 노드를 Q(방문되지 않은 노드들의 집합)에 추가
//요약하자면, Graph에 존재하는 모든 노드들을 초기화한 뒤, Q에 추가함.
while Q is not empty: // Q 집합이 공집합 아닐 경우, 루프 안으로!
u ← vertex in Q with min dist[u] // 첫번째 반복에서는 dist[source]=0이 선택됨. 즉, u=source에서 시작
remove u from Q // U 노드를 방문한 것이므로 Q집합에서 제거
for each neighbor v of u: // U의 이웃노드들과의 거리 측정
alt ← dist[u] + length(u, v) // 출발지 노드 부터 계산된 U노드까지의 거리 + V에서 U의 이웃노드까지의 거리
//= source to U + V to U = source to U
if alt < dist[v]: // 방금 V노드까지 계산한 거리(alt)가 이전에 V노드까지 계산된 거리(dist[v])보다 빠른 또는 가까운 경우
dist[v] ← alt // V에 기록된 소스부터 V까지의 최단거리를 방금 V노드까지 계산한 거리로 바꿈
prev[v] ← u // 제일 가까운 노드는 지금 방문하고 있는 노드(U)로 바꿈
return dist[], prev[] //계산된 거리값과 목적지를 리턴https://tinyurl.com/yyoa4tv2
Graph는 모든 노드와 노드 간의 거리, 이웃노드에 관한 정보를 포함한다.
Source는 출발할 노드를 의미한다.
prev[(node)]는 출발지까지 가장 빠르게 갈 수 있다고 계산된 이웃 노드를 가리킨다. 즉, 출발지부터 목적지까지의 경로가 아니라, 목적지부터 출발지까지의 경로를 기록한다.
dist[(node)]는 출발지부터 현재 node까지의 cost 값을 의미한다.
'알고리즘 공부' 카테고리의 다른 글
| 16. 크루스칼 알고리즘 (0) | 2019.10.04 |
|---|---|
| 15. 그리디 알고리즘 (동전, 거스름돈 문제) (0) | 2019.10.03 |
| 13. 카운팅 정렬(A.K.A 계수 정렬) (0) | 2019.09.29 |
| 12. 기수 정렬 (A.K.A Radix sort) (0) | 2019.09.29 |
| 11. 쉘 정렬 (0) | 2019.09.29 |



